tl;dr: This article discusses three generic hash-collision search methods: the birthday-paradox collision algorithm, Pollard’s rho with Floyd cycle detection, and the parallelizable Pollard’s lambda method based on Distinguished Points. These generic methods can be generalized in a similar way to integer factorization and discrete logarithm problems.
Disclaimer: This article is the English counterpart automatically generated from the original Chinese blog by Codex + GPT-5.4. The translation aims to preserve the original meaning, structure, and technical details as faithfully as possible. If there is any ambiguity or inaccuracy, please refer to the original Chinese version.
- Parallel Hash Collision Search by Rho Method with Distinguished Points: https://www.cs.csi.cuny.edu/~zhangx/papers/P_2018_LISAT_Weber_Zhang.pdf.
- HITCON 2023 challenge Collision: https://github.com/maple3142/My-CTF-Challenges/tree/master/HITCON%20CTF%202023/Collision.
Given a hash function \(\mathcal{H}: \{0,1\}^{*} \mapsto \{0,1\}^n\) with output length \(n\), how do we find two inputs \(x_1, x_2\) such that:
\[\mathcal{H}(x_1) = \mathcal{H}(x_2)\]The hash collision problem, or more precisely the second-preimage-style collision search considered here, is a fundamental problem in cryptography and appears throughout the entire discipline. The generic hash-collision algorithms discussed in this article can be divided into the following three categories:
| Algorithm | Time Complexity | Space Complexity | Parallelism |
|---|---|---|---|
| Birthday-paradox collision search | \(\mathcal{O}(2^{n/2})\) | \(\mathcal{O}(2^{n/2})\) | Parallelizable, but memory-intensive |
| Pollard’s rho | \(\mathcal{O}(2^{n/2})\) | \(\mathcal{O}(1)\) | No linear speed-up in parallel |
| Pollard’s lambda | \(\mathcal{O}(2^{n/2})\) | \(\mathcal{O}(k)\) (trade-off) | Parallelizable, often close to linear speed-up |
Birthday-Paradox Collision Search
The classical birthday paradox. A well-known question is: in a year with 365 days, how many people are needed so that the probability that at least two people share the same birthday exceeds 50%? Under a fully random model, the answer is 23, which is much smaller than intuition suggests.
Consider the generalized version: given \(k\) people, what is the probability that at least two of them share the same birthday? When \(k > 365\), this probability is 1 by the inclusion-exclusion principle. More generally, given a set of size \(N\), such as the output space of a hash function, we randomly sample \(k \le N\) values from the set with replacement. Let the probability that at least two sampled values are equal be denoted by \(\Pr\left(\text{coll}\right)\). Let \(\Pr\left(z=0\right)\) denote the event that all sampled values are distinct. Then \(\Pr\left(\text{coll}\right) = 1 - \Pr\left(z=0\right)\), where:
\[\Pr\left(z=0\right) = \frac{N}{N} \cdot \frac{N-1}{N} \cdot \frac{N-2}{N} \cdots \frac{N-k+1}{N}\]Hence the probability that two values coincide, i.e. that a collision occurs, is:
\[\Pr\left(\text{coll}\right) = 1 - \Pr\left(z=0\right)\]For the birthday-paradox problem, this probability exceeds 50% as soon as \(k \ge 23\). This is much smaller than most people would expect. More generally, when \(k\) is small relative to \(N\), we may use the approximation:
\[\Pr\left(\text{coll}\right) = 1 - \Pr\left(z=0\right) \approx 1 - e^{-\frac{k^2}{2N}} > 0.5 \\ \implies e^{-\frac{k^2}{2N}} \approx 0.5 \implies k \approx \sqrt{2N \ln(2)}\]For a hash function with output bit-length \(n\), we obtain
\[k \approx 1.177 \cdot 2^{n/2}\]This means that, by the birthday paradox, computing \(\mathcal{O}(2^{n/2})\) random hash values already gives a high probability of finding a collision.
- Initialize a dictionary with \(O(1)\) lookup time, where the key is a hash value and the value is the corresponding preimage.
- Randomly generate preimage-hash pairs \(\{x, \mathcal{H}(x)\}\) and insert them into the dictionary until a key collision occurs.
By the birthday paradox, this probabilistic algorithm terminates after \(\mathcal{O}(2^{n/2})\) hash evaluations, and its space complexity is \(\mathcal{O}(2^{n/2})\).
Pollard’s rho
Pollard’s rho method was originally developed as an integer-factorization algorithm. Its core intuition also comes from the birthday paradox. Since the generated sequence resembles the Greek letter \(\rho\), the method is called rho.
Pollard’s rho for Integer Factorization
Integer factorization problem. Given a composite integer \(n = p \cdot q\), how do we recover a non-trivial factor \(p\)?
For Pollard’s rho factorization algorithm, the key idea is to define a function \(g(x)\) that generates a pseudorandom sequence. For example, one may choose the polynomial \(g(x) = x^2 + 1 \bmod n\). This generates the following finite sequence
\[\left\{x_0, g(x_0), \cdots, g^k(x_0), \cdots \right\}\]where \(g^k\) denotes repeated composition, and we write \(x_k = g^k(x_0) \in \mathbb{Z}_n\). However, from the viewpoint modulo \(p\), the same sequence implicitly contains a subsequence:
\[\left\{x_0, g(x_0), \cdots, g^k(x_0), \cdots \right\} \bmod p\]which is a subsequence of \(\left\{x_k \bmod p\right\}\). If the chosen \(g(x)\) behaves randomly enough, then by the birthday paradox we expect a collision after about \(\mathcal{O}(\sqrt p)\) steps. This is illustrated by the point \(l_0\) in the figure below:

If the sequence values in Figure 1 are interpreted modulo \(p\), such a collision means that we have found
\[g(x_{l_0- 1}) = g(x_{l_0 + n}) \bmod p\]Since in practice we only see the sequence modulo \(n\), there is overwhelmingly high probability that
\[g(x_{l_0- 1}) \ne g(x_{l_0 + n}) \bmod n\]and therefore
\[\gcd\left(g(x_{l_0- 1}) - g(x_{l_0 + n}), n\right) = p\]reveals a factor of \(n\). However, during the sequence computation we cannot directly detect which values have collided; comparing against the whole previous sequence via repeated \(\gcd\) computations would be prohibitively expensive in both time and space. Therefore we need an efficient cycle-detection algorithm to assist Pollard’s rho.
Pollard’s rho is often combined with Floyd’s algorithm, which is vividly described as the tortoise and hare algorithm.
- Start both sequences from the same initial point \(x_0\). Let the slow sequence \(\{x^{(T)}_{i}\}\) use the update rule \(f_1(x) = g(x)\), and let the fast sequence \(\{x^{(H)}_{i}\}\) use \(f_2(x) = g(g(x))= g^2(x)\). We iteratively compute these sequences while storing only the current values \(x_k^{(T)}, x_{k}^{(H)}\).
- When \(l_0 < n\), after only \(n\) iterations we obtain \(x_m^{(T)} = x_{m}^{(H)} \bmod p\), because \(x_{m} = x_{2m} \bmod p\). Hence, while computing the two sequences, Floyd’s algorithm repeatedly evaluates \(\gcd\left(x_k^{(T)} - x_{k}^{(H)}, n\right)\), and as soon as this common divisor becomes non-trivial, we recover a prime factor \(p\).
For example, if the Floyd meeting point in Figure 1 occurs at the \(i\)-th node (in fact \(i = m\)), then the two values are congruent modulo \(p\) at that point, but with high probability not congruent modulo \(n\). Thus \(\gcd\left(x_i^{(T)} - x_{i}^{(H)}, n\right)\) also yields \(p\).
As for time complexity, the expected sequence length is \(l_0 + n \approx \mathcal{O}(\sqrt p)\). Since the slow sequence meets the fast sequence before traversing the entire \(\rho\)-shaped structure, the overall time complexity is \(\mathcal{O}(\sqrt p)\) and the space complexity is \(\mathcal{O}(1)\).
A simple implementation of Pollard’s rho is shown below:
# sage
def rho(n):
# Pollard's rho method
c = int(10)
a0 = int(1)
a1 = a0^2+c
a2 = a1^2+c
while gcd(n,a2-a1) == 1:
a1 = (a1^2+c) % n
a2 = (a2^2+c) % n
a2 = (a2^2+c) % n
g = gcd(n,a2-a1)
return [g,n//g]
Readers may wonder about the special role of the collision point \(l_0\). Let \(a= g(x_{l_0- 1}),\ b= g(x_{l_0 + n}),\ c = x_{l_0}\). In the factorization setting, where the pseudorandom sequence uses \(f(x) = x^2 + 1\), the collision at \(l_0\) means that we have found two distinct values \(a,b\) such that \(f(a) = f(b) = c\). In other words, \(a,b\) are two distinct solutions of
\[x^2 = c - 1 \bmod p\]and thus they are two quadratic residues in \(\mathbb{Z}_p\) satisfying \(a + b = 0 \bmod p\).
In the integer-factorization setting, we care about recovering the hidden modulus \(p\), so the rho collision point and the Floyd meeting point are effectively equivalent. But once we move to the hash-collision setting, the meanings of these two points diverge sharply. The hash-collision value is precisely the value at the collision point \(l_0\).
Pollard’s rho for Hash Collisions
Now move to the hash-collision setting. The pseudorandom sequence is generated by a hash function \(\mathcal{H}: \{0,1\}^{*} \mapsto \{0,1\}^n\), or by a composed map \(\mathcal{H}^{+} = \mathcal{H} \circ \mathcal{R}\). For simplicity, let the initial value be \(x_0\), and denote the update rule by \(x_{i+1} = H(x_i)\). In Figure 1, the cycle contains \(n+1\) points; let \(N = n + 1\).
Again, the pseudorandom sequence \(\{x_k\}\) collides after about \(k = \mathcal{O}(2^{n/2})\) steps, after which it enters a cycle. We use Floyd’s cycle-detection algorithm. Assume that the fast and slow sequences meet at point \(i\). At that moment, the slow sequence must still lie before the end of the first cycle traversal, so the number of sequence computations satisfies \(i \le l_0 + n\), and we have:
\[2*i - i = kn \implies i = k(n + 1) = kN\]It follows that \(k = \lceil \frac{l_0}{n} \rceil\). At this point, the two sequences meet at node \(i\), but this is not necessarily the collision point itself. We therefore want to continue until reaching \(l_0\). A useful observation is that the distances \(0 \rightarrow l_0\) and \(i \rightarrow l_0\) are equal modulo \(N = n + 1\). Indeed:
\[\left\{ \begin{aligned} d_1 &= l_0 + 1 + n - i \\ d_2 &= l_0 \end{aligned} \right.\]Thus
\[\begin{aligned} d_1 & = l_0 + n + 1 - i \bmod N \\ &= l_0 - kN \bmod N \\ &= l_0 \bmod N \\ &= d_2 \bmod N \end{aligned}\]Starting from point \(i\), the subsequent point sequence lies on a cycle of length \(N\). Therefore \(0 \rightarrow l_0\) and \(i \rightarrow l_0\) both reach \(l_0\) in exactly \(l_0\) slow steps. This lets us recover the two points \(x_{l_0 - 1}\) and \(x_{l_0 + n}\) that collide under the hash, with collision value \(x_{l_0}\).
Time-complexity analysis: once the meeting occurs, we keep the slow sequence fixed, return the fast sequence to the initial point \(0\), and then lower it to slow speed. After \(l_0\) additional steps, both sequences arrive at \(l_0\) and the hash collision is found. Hence the total number of hash evaluations is:
\[T = 3i + 2l_0, i = \lceil \frac{l_0}{n} \rceil (n+1)\]By the birthday paradox, we know that \(l_0 + n \approx \mathcal{O}(2^{n/2})\). Therefore the overall time complexity is upper-bounded by \(\mathcal{O}(5 \cdot 2^{n/2})\). Since we only need to maintain three pieces of state — the initial point, one slow-sequence node, and one fast-sequence node — the space complexity is \(\mathcal{O}(1)\).
Floyd’s algorithm is an efficient cycle-detection algorithm. Moreover, once the meeting point is known, it can quickly locate the actual collision point. This is why it is widely used across many cryptographic algorithms.
Pollard’s lambda
Although Pollard’s rho for hash collisions reaches the birthday-paradox bound and uses only constant memory, it does not admit linear speed-up under parallelization. On the other hand, the naive birthday-paradox method has enormous memory overhead in parallel and still does not behave well with respect to linear acceleration. So is there an algorithm that parallelizes nearly linearly while keeping memory usage low? Quisquater and Delescaille answered this question in the context of DES collision search by introducing Distinguished Points.
Distinguished-Point Collision Search
A Distinguished Point (DP) is selected by some conspicuous and easy-to-test property. In the hash-collision setting, we usually define a distinguished point as a hash value whose first \(k\) bits are all zero. That is, any hash value of the form \(\underbrace{00\cdots0}_{k} x_{k+1}\cdots x_{n}\) is called a distinguished point.
The DP collision algorithm then proceeds as follows, with distinguished-point parameter \(k\) fixed in advance:
- Randomly choose a start point \(S_i\), compute the hash sequence until a distinguished point \(D_i\) is reached, and store the DP chain \((S_i, D_i, L_i)\), where \(L_i\) is the chain length.
- Repeatedly choose different start points and generate such DP chains until two chains end at the same distinguished point \(D_i = D_j\).
- For two colliding chains \((S_i, D_i, L_i), (S_j, D_j, L_j)\), first advance the longer chain until the two remaining lengths match, then advance both chains together and test whether a real hash collision appears. If no collision is found, discard the shorter chain and return to step 1.
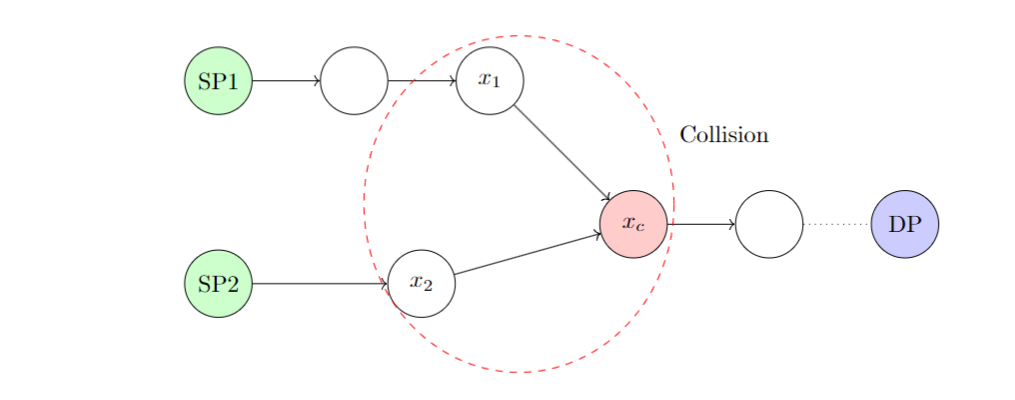
Figure 2 illustrates a collision structure arising in DP-based search. There, \(\mathcal{H}(x_1) = \mathcal{H}(x_2) = x_c\). The two chains share the same distinguished point but originate from different start points, which is what makes the collision possible. When the algorithm detects that the two chains in Figure 2 end at the same DP, the SP1 chain is longer than the SP2 chain by one step. Thus SP1 first performs one hash evaluation, after which SP1 and SP2 are advanced simultaneously, and the collision is then detected at \(x_1, x_2\).
If, after advancing SP1, it overlaps entirely with the SP2 chain, then this is only a pseudo-collision and the shorter chain is discarded. This situation is called the Robinhood Case, shown in Figure 3:
The Distinguished-Point collision algorithm is more widely known as Pollard’s lambda algorithm. The name comes from the shape of DP-chain collisions, which resembles the Greek letter \(\lambda\), as in Figure 2. Pollard’s lambda also applies to discrete logarithm computation, and is a general, efficient, and parallelizable algorithm for that problem as well.
Time-Space Trade-off
The time-space complexity of the Distinguished-Point collision algorithm depends heavily on the distinguished-point difficulty parameter. This notion is analogous to the difficulty parameter used in Bitcoin mining. Let the difficulty parameter be \(k\), meaning that the hash must begin with \(k\) leading zeros.
Analysis of the Distinguished-Point collision algorithm. The overall complexity can be decomposed into three phases: generating DP chains, obtaining a DP-chain collision, and recovering the actual hash collision.
- Generating DP chains: finding a DP chain is effectively a preimage search process, whose time complexity is \(\mathcal{O}(2^k)\).
- DP-chain collision: if we isolate the second phase, we are effectively looking for a second-preimage-style collision among DP chains. By the birthday paradox, the number of DP chains needed is \(\mathcal{O}(2^{(n-k)/2})\), and the corresponding space complexity is also \(\mathcal{O}(2^{(n-k)/2})\). However, this is not yet a hash collision, because it is a collision between two chains rather than between two points. If we analyze the process directly in terms of point collisions, then as soon as we have \(2^{n/2}\) points, a collision becomes likely. In the DP-chain view, this implies identical distinguished points. Therefore, the number of DP chains needed in the second phase is \(\mathcal{O}(\frac{2^{n/2}}{2^{k}}) = \mathcal{O}(2^{n/2 - k})\), and the space complexity is likewise \(\mathcal{O}(2^{n/2 - k})\).
- Recovering the actual hash collision: once two DP chains collide, locating the real hash-collision position costs \(\mathcal{O}(2^k)\).
Putting these together, the time and space complexity of the Distinguished-Point collision algorithm are:
- Time complexity: \(\mathcal{O}(2^{n/2} + 2^k) = \mathcal{O}(2^{n/2})\)
- Space complexity: \(\mathcal{O}(2^{n/2 - k})\)
This is the idealized analysis, ignoring exceptional situations such as the Robinhood Case. In practice, if \(k\) is too small, the space complexity becomes large. If \(k\) is too large, pseudo-collisions of the Robinhood type occur frequently, which increases the running time. Therefore the choice of difficulty parameter \(k\) is crucial for the Distinguished-Point method.
It is worth emphasizing that with a suitable choice of \(k\), the Distinguished-Point algorithm can keep the time complexity close to \(2^{n/2}\), avoid severe memory pressure, and still maintain essentially linear speed-up on multi-core hardware. For example, when \(n = 64\) and we choose \(k = 24\), the time complexity is \(\mathcal{O}(2^{32})\) and the memory complexity is \(\mathcal{O}(2^{8})\), which makes parallel linear acceleration practical. Below are the author’s experimental results for finding collisions on the lower 64 bits of SHA-256:
-
4 cores (with PRNG seed
0x123456789abcdef0)Two DP chains collided with dp mask=ffffff Number of chains find: 393 diff = 11897207 Looking for collision... Collision found! with 4 cores 333412288b678e3b ff7cb8a664c810e3 962860fc377014f1 962860fc377014f1 real 1m17.441s user 5m9.708s sys 0m0.020s -
8 cores (with PRNG seed
0x123456789abcdef0)Two DP chains collided with dp mask=ffffff Number of chains find: 409 diff = 11897207 Looking for collision... Collision found! with 8 cores 333412288b678e3b ff7cb8a664c810e3 962860fc377014f1 962860fc377014f1 real 0m45.683s user 6m5.344s sys 0m0.011s
The above experiments use an efficient C++ implementation of the DP collision algorithm adapted from the HITCON 2023 Collision challenge.
These results are broadly consistent with linear acceleration. Theoretically, the expected number of DP chains is \(2^8 = 256\), while the observed value is around 400. This is because the birthday-paradox estimate \(\mathcal{O}(1.117 \cdot 2^{n/2})\) corresponds to the point where the collision probability is just slightly above 50%.