概要: 本文讨论三类通用哈希碰撞搜索方法:基于生日悖论的碰撞算法(Birthday Paradox)、结合 Floyd 循环检测的 Pollard’s rho 算法,以及可并行的 Pollard’s Lambda 算法(Distinguished Points),这些通用算法可以类似地泛化到整数分解和离散对数问题的求解。
- Parallel Hash Collision Search by Rho Method with Distinguished Points: https://www.cs.csi.cuny.edu/~zhangx/papers/P_2018_LISAT_Weber_Zhang.pdf.
- HITCON 2023 赛题 Collision: https://github.com/maple3142/My-CTF-Challenges/tree/master/HITCON%20CTF%202023/Collision.
给定一个输出长度为 \(n\) 的哈希函数 \(\mathcal{H}: \{0,1\}^{*} \mapsto \{0,1\}^n\),如何找到两个输入 \(x_1, x_2\) 使得:
\[\mathcal{H}(x_1) = \mathcal{H}(x_2)\]哈希碰撞问题(第二原像攻击)是一个基础性的密码学问题,其几乎贯彻了整个密码学体系。本文介绍的通用哈希碰撞算法分为下面三类:
| 算法 | 时间复杂度 | 空间复杂度 | 并行性 |
|---|---|---|---|
| 生日悖论碰撞算法 | \(\mathcal{O}(2^{n/2})\) | \(\mathcal{O}(2^{n/2})\) | 可并行,但内存开销大 |
| Pollard’s rho 算法 | \(\mathcal{O}(2^{n/2})\) | \(\mathcal{O}(1)\) | 不可线性并行加速 |
| Pollard’s lambda 算法 | \(\mathcal{O}(2^{n/2})\) | \(\mathcal{O}(k)\) (可权衡) | 可并行,通常可接近线性加速 |
生日悖论碰撞算法
经典生日悖论。 一个经典的问题:在一个有 365 天的年份中,需要多少个人才能使得至少两个人有相同生日的概率超过 50%?在完全随机的情况下,理论值是 23 ,这比直觉上要少得多。
考虑一般化的版本:给定 \(k\) 个人,至少有两个人同一生日的概率是多少?在 \(k > 365\) 时,由容斥原理,这个概率为 1。进一步地,给定一个大小为 \(N\) 的集合(比如哈希函数输出空间),随机选择 \(k \le N\) 个集合内的值(有放回抽取),至少有两个相同值的概率记为 \(\Pr\left(\text{coll}\right)\)。令 \(\Pr\left(z=0\right)\) 代表所有选择的值均互异,则 \(\Pr\left(\text{coll}\right) = 1 - \Pr\left(z=0\right)\),其中:
\[\Pr\left(z=0\right) = \frac{N}{N} \cdot \frac{N-1}{N} \cdot \frac{N-2}{N} \cdots \frac{N-k+1}{N}\]因此有两个相同值的概率(即碰撞)是:
\[\Pr\left(\text{coll}\right) = 1 - \Pr\left(z=0\right)\]对于生日悖论问题,只要 \(k \ge 23\),这个概率就超过了 50%。这比大多数人预期的要少得多。一般地,当 \(k\) 相对于 \(N\) 较小时,使用近似公式有:
\[\Pr\left(\text{coll}\right) = 1 - \Pr\left(z=0\right) \approx 1 - e^{-\frac{k^2}{2N}} > 0.5 \\ \implies e^{-\frac{k^2}{2N}} \approx 0.5 \implies k \approx \sqrt{2N \ln(2)}\]对于输出比特长度为 \(n\) 的哈希函数,得到
\[k \approx 1.177 \cdot 2^{n/2}\]这意味着,利用生日悖论,我们需要计算 \(\mathcal{O}(2^{n/2})\) 个随机的哈希值,就有很大概率得到碰撞。
- 初始化一个字典,查询效率为 \(O(1)\),键(key)为哈希值,值(value)为哈希值对应的原像。
- 随机生成原像、哈希值对 \(\{x, \mathcal{H}(x)\}\),插入上述字典,直至键值发生碰撞。
根据生日悖论原理,上述概率性算法在 \(\mathcal{O}(2^{n/2})\) 个哈希值操作后结束,空间复杂度为 \(\mathcal{O}(2^{n/2})\)。
Pollard’s rho 算法
Pollard’s rho method 最初是整数分解中的一类算法,其核心原理也是 Birthday Paradox。因其生成序列的性质酷似希腊字母 \(\rho\),故而得名 rho。
整数分解的 Pollard’s rho 算法
整数分解问题. 给定一个合数 \(n = p \cdot q\),如何找到它的一个非平凡因子 \(p\)?
对于整数分解的 Pollard’s rho 算法,核心在于定义一个函数 \(g(x)\) 用于生成伪随机数序列,例如我们取一个多项式 \(g(x) = x^2 + 1 \bmod n\)。这会生成下面的有限序列
\[\left\{x_0, g(x_0), \cdots, g^k(x_0), \cdots \right\}\]其中 \(g^k\) 代表映射复合,记 \(x_k = g^k(x_0) \in \mathbb{Z}_n\)。但是,如果我们从模 \(p\) 的视角来看,同样上述序列其实隐藏了一个子群序列:
\[\left\{x_0, g(x_0), \cdots, g^k(x_0), \cdots \right\} \bmod p\]其是 \(\left\{x_k \bmod p\right\}\) 的子序列。如果我们选取的 \(g(x)\) 足够随机,根据生日悖论,我们大概会在 \(\mathcal{O}(\sqrt p)\) 后找到碰撞。如下图 \(l_0\) 所示:

如果图 1 中序列值代表的是模 \(p\) 的序列,这样的碰撞代表着我们寻找到了 \(g(x_{l_0- 1}) = g(x_{l_0 + n}) \bmod p\)。由于我们只有模 \(n\) 的序列,因此有极大概率在模 \(n\) 的序列下 \(g(x_{l_0- 1}) \ne g(x_{l_0 + n}) \bmod n\),于是
\[\gcd\left(g(x_{l_0- 1}) - g(x_{l_0 + n}), n\right) = p\]即可分解 \(n\)。但是,值得注意的是,在计算序列时无法直接判断哪个值发生了碰撞;如果需要和之前的序列进行逐次 \(\gcd\),其时间和空间开销都非常巨大。因此我们需要一个高效的循环检测算法来辅助 Pollard’s rho 算法。
Pollard’s rho 算法常常与 Floyd 算法配合使用,被形象地称为龟兔赛跑算法(Tortoise and Hare Algorithm)。
- 设置初始点相同 \(x_0\),一个慢速序列 \(\{x^{(T)}_{i}\}\) 的生成函数为 \(f_1(x) = g(x)\),另一个快速序列 \(\{x^{(H)}_{i}\}\) 的生成函数为 \(f_2(x) = g(g(x))= g^2(x)\)。我们逐次计算上面两个序列,并且只保留当前值 \(x_k^{(T)}, x_{k}^{(H)}\)。
- 在 \(l_0 < n\) 时,只需要 \(n\) 次迭代,即可得到 \(x_m^{(T)} = x_{m}^{(H)} \bmod p\),因为 \(x_{m} = x_{2m} \bmod p\)。因此 Floyd 算法在迭代计算两个序列的同时,每次尝试计算 \(\gcd\left(x_k^{(T)} - x_{k}^{(H)}, n\right)\),一旦上述公因子不为 0,即分解得到一个素因子 \(p\)。
例如图 1 中得到 Floyd 的碰撞点在第 \(i\) 个点(实际上 \(i = m\)),那么在 \(i\) 点两个值模 \(p\) 同余,但是大概率模 \(n\) 不同余,因此也能通过分解 \(\gcd\left(x_i^{(T)} - x_{i}^{(H)}, n\right)\) 得到 \(p\)。
考虑时间复杂度,期望的序列长度 \(l_0 + n \approx \mathcal{O}(\sqrt p)\)。因为慢速的序列会在走完整个 \(\rho\) 形序列之前与快速的序列发生碰撞,因此整个算法的时间复杂度为 \(\mathcal{O}(\sqrt p)\),空间复杂度为 \(\mathcal{O}(1)\)。
一个简单的 Pollard’s rho 算法如下:
# sage
def rho(n):
# Pollard's rho method
c = int(10)
a0 = int(1)
a1 = a0^2+c
a2 = a1^2+c
while gcd(n,a2-a1) == 1:
a1 = (a1^2+c) % n
a2 = (a2^2+c) % n
a2 = (a2^2+c) % n
g = gcd(n,a2-a1)
return [g,n//g]
读者可能会好奇碰撞点 \(l_0\) 的特殊之处。记 \(a= g(x_{l_0- 1}),\ b= g(x_{l_0 + n}),\ c = x_{l_0}\),在整数分解的场景下,伪随机序列的生成函数选取为 \(f(x) = x^2 + 1\),点 \(l_0\) 处的碰撞实际上就是寻找到了两个不同的值 \(a,b\) 使得 \(f(a) = f(b) = c\),即 \(a,b\) 是
\[x^2 = c - 1 \bmod p\]的两个互异解,因此 \(a,b\) 即为 \(\mathbb{Z}_p\) 上的两个二次剩余,满足 \(a + b = 0 \bmod p\)。
在整数分解的场景下,由于我们需要得到隐藏序列的模数 \(p\),rho 碰撞点与 Floyd 相遇点没有区别;而一旦我们迁移到哈希碰撞的角度看,这两个点的意义就截然不同了。哈希碰撞的哈希值即为碰撞点 \(l_0\) 的值。
哈希碰撞的 Pollard’s rho 算法
迁移到哈希碰撞的场景,此时伪随机序列的生成函数为哈希函数 \(\mathcal{H}: \{0,1\}^{*} \mapsto \{0,1\}^n\),或者某个复合哈希映射 \(\mathcal{H}^{+} = \mathcal{H} \circ \mathcal{R}\)。简便起见,初始值为 \(x_0\),我们使用 \(\mathcal{H}\) 表示伪随机序列的生成函数:\(x_{i+1} = H(x_i)\)。图 1 中环有 \(n+1\) 个点,记 \(N = n + 1\)。
同样地,伪随机序列 \(\{x_k\}\) 会在 \(k = \mathcal{O}(2^{n/2})\) 处发生碰撞,之后进入循环。采用 Floyd 算法进行循环检测(cycle detection),假设在点 \(i\) 为 Floyd 快速序列和慢速序列的相遇点,在这一点相遇时,慢速序列一定处于第一次 cycle 结束之前,因此序列计算次数为 \(i \le l_0 + n\),有如下关系:
\[2*i - i = kn \implies i = k(n + 1) = kN\]容易得出 \(k = \lceil \frac{l_0}{n} \rceil\)。此时,\(i\) 点相遇,但是不一定发生碰撞,因此我们想要继续行进到点 \(l_0\)。一个有趣的观察是 \(0 \rightarrow l_0\) 和 \(i \rightarrow l_0\) 的距离一定是相等的(模 \(N = n + 1\) 意义下)。证明如下:
\[\left\{ \begin{aligned} d_1 &= l_0 + 1 + n - i \\ d_2 &= l_0 \end{aligned} \right.\]故而
\[\begin{aligned} d_1 & = l_0 + n + 1 - i \bmod N \\ &= l_0 - kN \bmod N \\ &= l_0 \bmod N \\ &= d_2 \bmod N \end{aligned}\]以 \(i\) 点为起始点,后续点集序列将会是一个长度为 \(N\) 的循环,因此 \(0 \rightarrow l_0\) 和 \(i \rightarrow l_0\) 将会以相同的步数 \(l_0\) 达到 \(l_0\) 点(均慢速),从而检测得到 \(x_{l_0 - 1}\) 和 \(x_{l_0 + n}\) 两个点发生哈希碰撞,碰撞的哈希值为 \(x_{l_0}\)。
时间复杂度分析:发生碰撞后,我们让慢速序列保持不变,快速序列返回到初始点 \(0\),速度降为慢速,经过 \(l_0\) 步之后最终均到达点 \(l_0\),找到哈希碰撞。因此整个序列中计算哈希的总次数就是:
\[T = 3i + 2l_0, i = \lceil \frac{l_0}{n} \rceil (n+1)\]根据生日悖论,我们知道 \(l_0 + n \approx \mathcal{O}(2^{n/2})\),故算法的总体时间复杂度不超过 \(\mathcal{O}(5 \cdot 2^{n/2})\)。由于只需要维护三个点的信息(起始点、一个慢速序列的节点、一个快速序列的节点),空间复杂度是 \(\mathcal{O}(1)\)。
Floyd 算法是一种有效的循环检测算法(Cycle Detection),并且从相遇点(Meeting Point)能够快速定位到碰撞点(Collision Point),在许多密码学算法中都有非常广泛的应用。
Pollard’s lambda 算法
Pollard’s rho 哈希碰撞算法虽然时间复杂度满足生日悖论的界,并且只需要常量内存,但是它不能通过并行计算进行线性的加速;朴素的生日悖论碰撞并行的空间开销巨大,并且也很难满足线性的加速。那么是否存在一种算法,使得其在并行环境中能够线性加速,并且空间复杂度也不高呢?Quisquater 和 Delescaille 在寻找 DES 的碰撞时,就使用了 Distinguished Point 来辅助碰撞。
Distinguished Point 碰撞算法
显著点(DP)是根据显著且易于测试的属性来选择的。对于哈希碰撞,我们一般把显著点选取为前 \(k\) 个比特均为 0 的哈希点。即形如 \(\underbrace{00\cdots0}_{k} x_{k+1}\cdots x_{n}\) 的哈希值,称为一个显著点。
于是 DP 哈希碰撞算法主要包含下面的步骤,预定义显著点参数为 \(k\):
- 随机选取一个初始点 \(S_i\)(start point),计算哈希序列,直至得到一个显著点 \(D_i\),保存一条 DP 链 \((S_i, D_i, L_i)\),其中 \(L_i\) 为长度信息。
- 不断选取不同的初始点,寻找上述 DP 链,直到显著点发生碰撞 \(D_i = D_j\),此时停止寻找 DP 链。
- 选取发生碰撞的两条链 \((S_i, D_i, L_i), (S_j, D_j, L_j)\),先对较长的链进行计算,直至剩余长度与另一条保持一致,之后两条链一起计算,检测是否出现哈希碰撞。如果没有碰撞,丢弃较短的链,继续回到第一步寻找其他的 DP 链。
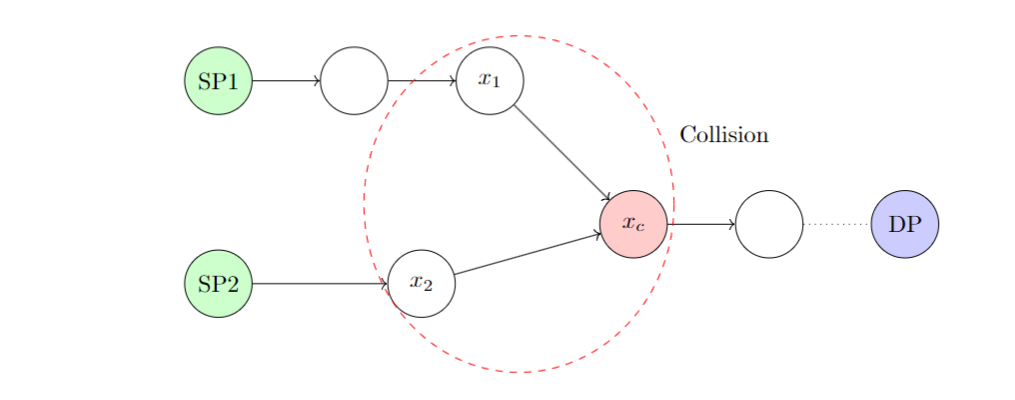
图 2 是 DP 碰撞搜索中生成的碰撞示意图。图中 \(\mathcal{H}(x_1) = \mathcal{H}(x_2) = x_c\),它们的显著点 DP 相同,但是位于不同的起点上,从而导致碰撞出现。检测到图 2 中 DP 相同的链出现时,由于 SP1 链比 SP2 链长 1,于是 SP1 首先进行 1 次哈希,此后 SP1 和 SP2 同时进行哈希,之后在 \(x_1, x_2\) 处检测到碰撞。
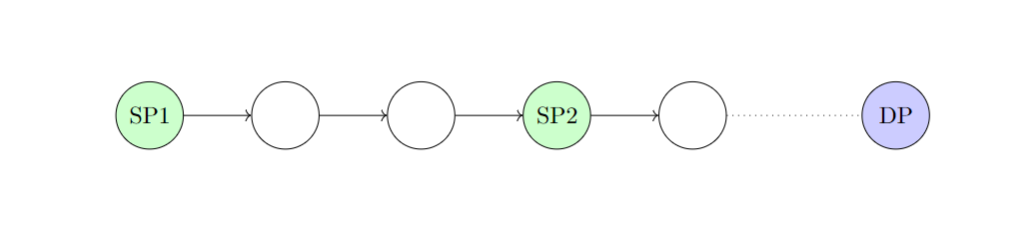
如果 SP1 链移动后发现与 SP2 链重合,则这是一次伪哈希碰撞,丢弃较短的链。这种情况被称为 Robinhood Case,如图 3 所示:
Distinguished Point 碰撞算法更广为人知的一个名字是 Pollard’s lambda 算法,源自于 DP 链碰撞的图形(参考图 2)酷似希腊字母 \(\lambda\) 而得名。Pollard’s lambda 算法同样也适用于离散对数的求解,是一种通用、高效、可并行的离散对数求解算法。
时间空间复杂度权衡
Distinguished Point 碰撞算法的时间空间复杂度,很大程度上与 Distinguished Point 的难度系数有关(Difficulty)。这里的难度系数定义和比特币挖矿算法的难度系数定义是一致的。记难度系数为 \(k\):哈希值为前置 \(k\) 个 0。
Distinguished Point 碰撞算法分析. 整个算法考虑三个阶段的复杂度:DP 链的生成 + DP 链碰撞的过程 + 恢复哈希碰撞。
- DP 链的生成:寻找 DP 链的过程是第一原像攻击(Preimage Attack),其时间复杂度是 \(\mathcal{O}(2^k)\)。
- DP 链碰撞:单独分析第二阶段 DP 链碰撞的过程是第二原像攻击,即哈希碰撞。根据生日悖论,找到碰撞需要生成的 DP 链数目是 \(\mathcal{O}(2^{(n-k)/2})\),空间复杂度也就是 \(\mathcal{O}(2^{(n-k)/2})\)。但这与哈希碰撞并不同,这是两条链的碰撞,而不是点的碰撞! 因此如果要从生日悖论的角度分析,我们仍然分析点的碰撞,只要有 \(2^{n/2}\) 个点,就可能发生碰撞;对应到 DP 链上,一定会导致显著点(DP)相同。因此第二阶段的碰撞,需要 DP 链的数目为 \(\mathcal{O}(\frac{2^{n/2}}{2^{k}}) = \mathcal{O}(2^{n/2 - k})\),空间复杂度也就是 \(\mathcal{O}(2^{n/2 - k})\)。
- 恢复哈希碰撞:DP 链发生碰撞后,寻找哈希碰撞位置的时间复杂度为 \(\mathcal{O}(2^k)\)。
综合上述分析,Distinguished Point 碰撞算法的时间空间复杂度如下:
- 时间复杂度:\(\mathcal{O}(2^{n/2} + 2^k) = \mathcal{O}(2^{n/2})\)
- 空间复杂度:\(\mathcal{O}(2^{n/2 - k})\)
这是理想分析下的结果,尚不考虑特殊情况如 Robinhood Case 的出现。实际上,如果 \(k\) 值取得太小,空间复杂度高;如果 \(k\) 选取得太大,会频繁出现 Robinhood Case 的伪碰撞,导致时间复杂度增加。因此难度系数 \(k\) 的选取对 Distinguished Point 算法非常关键。
值得指出的是,通过精心选取 \(k\),Distinguished Point 算法既能保证时间复杂度基本在 \(2^{n/2}\) 附近,不是内存困难的,并且在多核并行下保持线性的加速。比如 \(n = 64\),选择 \(k = 24\),时间复杂度 \(\mathcal{O}(2^{32})\),内存复杂度 \(\mathcal{O}(2^{8})\),在此情况下可以进行线性加速的并行。下面是笔者对 sha256 的低 64 位进行碰撞的实验数据:
-
4 核(PRNG 的 SEED 为
0x123456789abcdef0)Two DP chains collided with dp mask=ffffff Number of chains find: 393 diff = 11897207 Looking for collision... Collision found! with 4 cores 333412288b678e3b ff7cb8a664c810e3 962860fc377014f1 962860fc377014f1 real 1m17.441s user 5m9.708s sys 0m0.020s -
8 核(PRNG 的 SEED 为
0x123456789abcdef0)Two DP chains collided with dp mask=ffffff Number of chains find: 409 diff = 11897207 Looking for collision... Collision found! with 8 cores 333412288b678e3b ff7cb8a664c810e3 962860fc377014f1 962860fc377014f1 real 0m45.683s user 6m5.344s sys 0m0.011s
上述实验使用了来自 Hitcon 2023 Collision 赛题的一个高效 C++ 实现的 DP 碰撞算法。
上述结果基本符合线性的加速。理论上期望的 DP 链数目为 \(2^8 = 256\),实际 400 左右略高,是因为生日悖论给出的估计 \(\mathcal{O}(1.117 \cdot 2^{n/2})\) 是碰撞概率刚好大于 50% 时的哈希次数。